Data analysis is a form of software engineering
When I started getting excited about data science 7 years ago, I was also at the same time just learning how to program. Like…not how to program k-means from scratch, like how to draw circles in Javascript.
As such, I was learning multiple technical concepts at the same time:
Since then, I’ve collected some wins under my belt as a data scientist. But my best learnings actually came from making mistakes – writing inefficient Hive queries, making low-accuracy or over-engineered models, being overly academic about metric definitions, waiting too long to show business users intermediate progress, etc.
One of the biggest conceptual errors I made starting out in data science was thinking that data analysis was somehow a different, special, disjoint field from software engineering. I’m taking a few hours to write up – and draw up! – my past and current beliefs on this topic.
If you’re busy and only have a few minutes, the main thrust of this post is that data analysis best practices/tools are starting to strongly resemble practices/tools from software engineering and this is a trend I’d expect to continue.
Here’s my experience on this subject represented visually:

If you’d like a more guided tour, please do feel free to read on.
A call to adventure (🎵 here) #
When I started becoming a technical individual contributor, I was scared of “real programming” – which, to me, meant: building features for a web/mobile application, running/maintaining a server, ensuring consistency across multiple database copies,1 using version control, issuing 😱 pull requests 😱. I was much more comfortable with “data science” or data analysis, which shared a lot of familiar tools like regression with my undergraduate degree in economics.
Now that I’ve worked in data science at multiple organizations in the US/SEA on different analytics problems, when I look back at the concept of data science, I can’t help but feel much like what I imagine Odysseus felt like when returning to Ithaca after battling Sirens and other mythical creatures, or Frodo when returning to The Shire after destroying The One Ring in the fiery chasm of Mount Doom – once you’ve travelled on a long, epic journey, your home never quite looks the same:

That is, I know realize software engineering and data analytics are different heads of the same Hydra, they are inextricably linked – specifically, data analytics is a subset of software engineering! And one that I think will overlap more and more with software engineering in the future, which I’ll now go into more detail to describe.
My past state of the world (circa 2014) #
When I started, I basically knew nothing about either of these subjects, and while it’s always difficult to re-create your old un-informed perspective, as I recall my mental model was something like this:
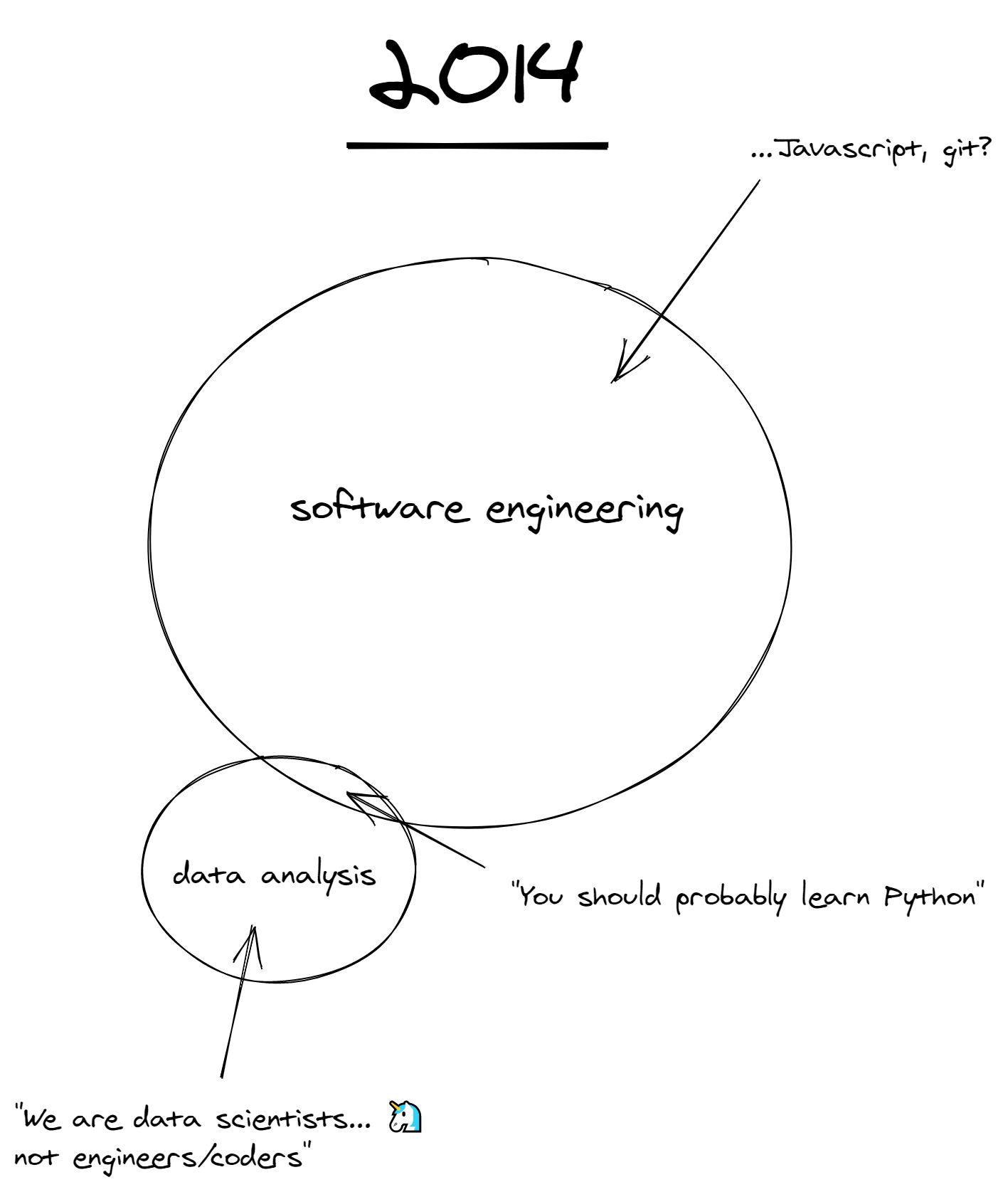
Software engineering was basically black magic to me – it was writing code that powered websites, mobile apps, etc. – that I barely had any understanding of. In contrast, data analysis, or “data science” as it eventually became branded, was something I could wrap my head around – it seemingly entailed digging into patterns of user behavior, looking for trends, making models to understand causal relationships, etc.2
Whereas the tools of software engineering were “real coding languages” like Java, Javascript, Ruby, I perceived data science to be using “less hard-core ones” like SQL, Python, and R. Now, as someone who’s dabbled in a bit of everything, I realize such hierarchies are quite silly and always extremely reductive!
Further, everything in my comic representation is quite small, because software was just starting to eat the world and data wasn’t yet the new oil. Even though I was excited about, and a practitioner in, data science (and, by extension, software engineering), I still under-estimated how many advances would be made in the fields in just 7 short years.
My current state of the world (2021) #
Here’s how I currently see software engineering and data analysis roughly:

That is, some things (building CRUD mobile web/apps, etc.) are pure software engineering, and some things are pure data analysis (making metric definitions with business users, etc.). However, their intersection is large and growing.
What’s going on at this intersection? #
There’s some really fascinating stuff going on here, let’s dive deep for a second here!
Full-stack ML models #
Most business users don’t want black box models – even if you can show empirically they are 98% accurate. There’s always the chance that your train/test split wasn’t as generalizable as you claim, there could be a structural shift in their industry that a model might not pick up, or they might just be suspicious of ML in general.
Enter full-stack ML models, where a model’s inputs, predictions, explanations, and confidence scores can be presented to the decision-maker in a familiar graphical interface. Even better if you can allow the user to correct mis-predictions in the interface, and feed those back into the model. Tools like Streamlit make it so that machine learning developers can build interfaces without ever leaving Python or worrying too much about deployment.
Metric definitions as code #
When data analytics was just starting, there simply wasn’t enough time to worry too much about aligning a single source of truth for or versioning metric definitions. It was probably common for them to only exist in one place, so why even worry about this? If you want to know what the definition of weekly active users is, you could just look at the underlying SQL in the 2-3 reporting dashboards.
However, now that it’s common to have 50-, 100-, or 500-person analytics teams and million-dollar business decisions made off of dashboards and metrics, we, as an industry, are realizing we need to take this issue a little more seriously.
If Alice the Pricing Data Scientist makes a dashboard that refers to weekly active users and Bob the Search Data Scientist does a deep-dive in a Python notebook on some new feature that also refers to weekly active users, the definition – in code – of those two things should be exactly the same, lest total confusion, frustration, and crises of faith ensue. The situation gets even worse if Alice and Bob were from different departments, who might not even share toolsets. That is, “weekly active users” must become weekly active users.
Large companies have centralized data engineering teams to tackle this over multi-year efforts; for those with smaller data teams, it’s probably better just to go with a pay-per-seat tool like dbt, once you have >10 folks creating and reporting on metrics.
And more #
There’s actually a bunch of other sub-themes in this area I am only starting to explore.
One is automated data quality tests. That is, rather than waiting for a business user to wonder why his team’s KPI inexplicably shot up 30% overnight, when we know 80-90% of the time it’s a data quality issue not a real effect, there will need to be data quality monitoring tools that work across multiple source types, interop with different kinds of databases, etc. I haven’t found an open-source effort or company product doing this well enough yet for my purposes, but am looking!
Data version control is also an interesting concept that my team has started to dip our toes into. No consensus yet, but it seems like a natural tool that will need to be adopted into the machine learning developer’s toolset if she is working on the same model for more than a few months, and doesn’t want to have to look through _v11, _v12 of her past training datasets to find the one that had a good or otherwise memorable result.
Summary #
More and more, software engineering practices are becoming standard data analysis practices. Metric and data versioning are just generalizations of shared code repo practices that SWEs have been using for decades, data quality tests are basically just data-specific unit tests and PagerDuty norms, now long established in SWE ways of working.
I think I’ve realized this because I’ve become less afraid of “crunchy” software engineering problems, and am starting to see that taking a software engineering approach to data analysis yields better and more sustainable results.
Future data tooling landscape (2028) #
The only reliable way to predict the future is to build it, but I’ll hazard some rough guesses of where I see the data tooling landscape going. I expect to continue to see growth in both the software engineering and data analysis fields, but with more software engineering practices being adapted to data analysis workflows.
Or visually:
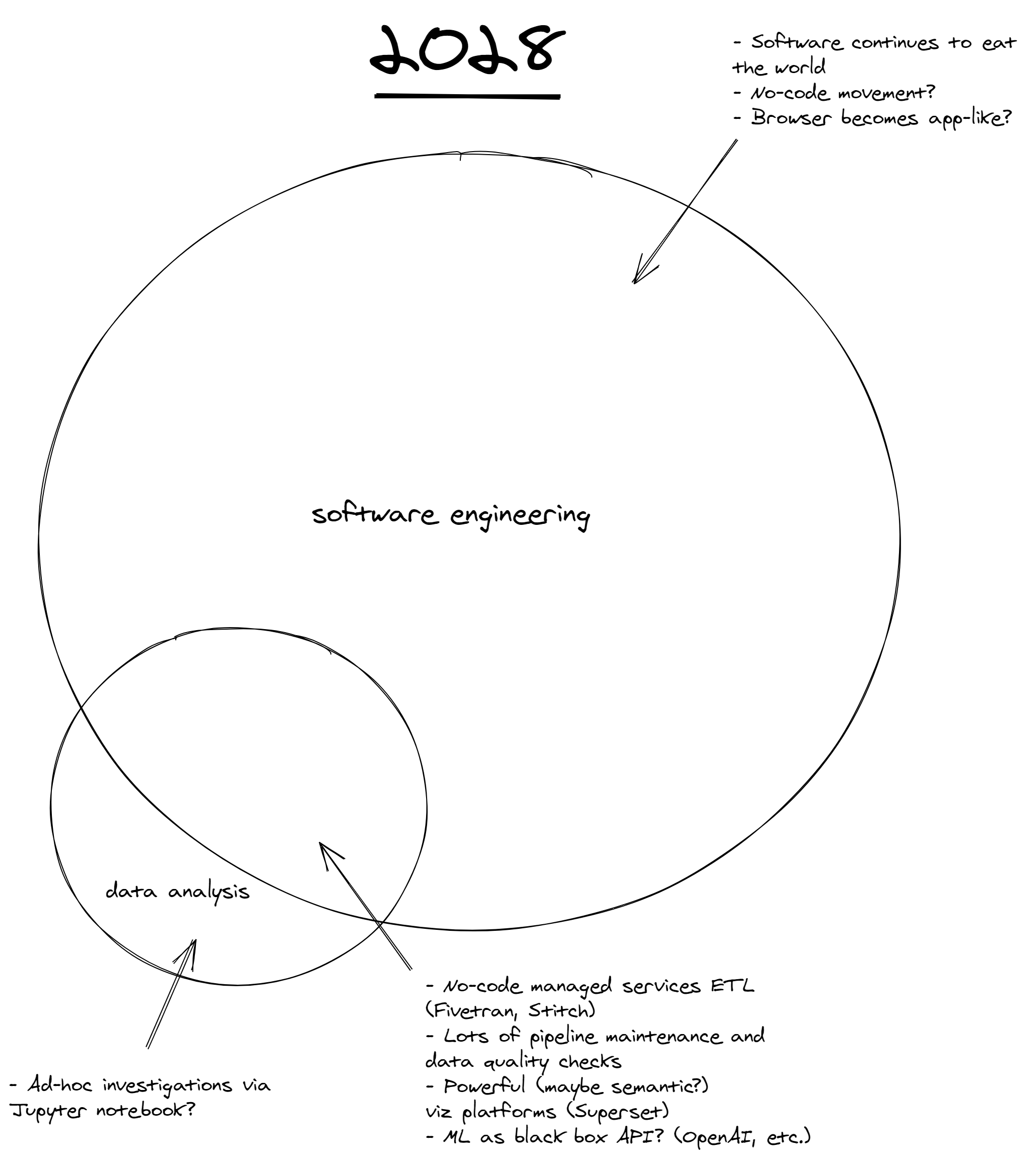
Everything is bigger, because software and data are just so much more important to every business, every vertical, every industry. But also notice that data analysis has started to ~65% overlap with software engineering!
What might happen at this intersection? #
Let’s zoom in again!
Making ingestion easier? #
Low- or no-code ETL managed services like Fivetran and Stitch will certainly continue to build more integrations, become more performant, and, eventually, lower their prices. In this future, for businesses with no existing modern data warehouse (~75-90% in Southeast Asia if I were to speculate), you could get something basic up and running with just the credentials to their most important SaaS-based data sources (e.g. Salesforce, Google Analytics, etc.).
This is already somewhat possible today, but in my experience, often a company’s most important data sources (e.g. POS system, ERP system, facilities, manufacturing, trading systems) are still either on-premise or don’t yet have pre-built, easy-to-use connectors. So, there is still significant data engineering work to just to get started with modern data analysis techniques. I believe – perhaps wishfully – this time to set-up will go down in the future.
More powerful visualization & exploration tools? #
Like Craigslist’s many sub-marketplaces were bled off into more specific, purpose-built alternatives (e.g. Airbnb for short-term housing, Stubhub for tickets), the Jupyter notebook of 2021 is doing so many core data analysis functions that I expect it will be similarly “unbundled,” though perhaps less dramatically.

The future of the Jupyter notebook? Source
In particular, I find the Jupyter notebook flow of pandas, matplotlib, etc. super clunky for the initial data exploration and cleaning phase of data work. It feels like it hasn’t been meaningfully improved on since I started in the industry 7 years ago. Increasingly, I am starting to rely on more powerful data visualization tools like Apache Superset to do this and, in the future, I expect there will be a proliferation in this field.
Further, if someone is able to finally come up with an interactive, semantic data visualization tool (e.g. “How has the usage of type X users been like since YYYY?”) that actually produces better findings than 3-5h of a good data analyst’s time (e.g. that isn’t just a marketing toy), that product will be worth billions. There are several trying, I’m not aware of any true solutions there, but am keeping my eye out.
ML as a black-box? #
With more and more API-based microservices for the most common machine learning tasks – such as Google Language API for sentiment, entity extraction, translation, Google Vision API for image recognition and classification, OpenAI for a general-purpose language model – I believe two things will happen.3
First, it will be quite easy to get good baseline performance with an out-of-the-box-solution so the bar to build a custom, purpose-built machine learning model will continue to get higher and higher. Second, more work will be focused on stitching together the output of multiple models and make sure data is reliably being fed into them, and implicitly away from the work of developing high-accuracy, performant ones for individual tasks. Note that the first is the classic machine learning development flow and the second is more of a classic data/software engineering task.
Pipelines, pipelines everywhere?! #
Airflow DAGs, cron jobs, Cloud Run jobs, SFTP batch loads, Kafka topics. It’s already a mess today, what will it be like in 7 years? The one guarantee I have is that data engineering tools & approaches that can keep this mess running reliably, transparently, and easily will continue to be the real 10x tool in a data scientist’s toolkit. The most elegant models, visualizations and insights all crumble in the face of bad data.
Thanks #
Thanks so much for reading. I am always looking for more tools to evaluate and for my team to try. If you have a favorite that was missing here, or an area you feel was under-represented or wrongly portrayed, please do reach out over Twitter or email at nicholas.e.huber@gmail.com!
Thanks to Enzo Ampil and Nick Khaw for reading drafts of this.
1 Though I actually wouldn’t have been able to describe it like this.
2 I hadn’t even started learning about A/B testing and the fascinating rabbit hole of product experimentation.
3 I know I said business users don’t want black-box models, but this is about developers, and most good developers are so overwhelmed with requests on their time, they’ll just use the best tool for the job.
More recommended reading: #
- a16z’s modern data infrastructure landscape post
- Matt Turck’s 2020 AI/ML landscape
- Technically’s breakdown of what tools your data team is using
- Jackson Mohsenin’s Interfaces for ML post