Learnings after working in AI for 9 months
When I moved back to the US a year ago, I would cringe inside a bit when I saw a tweet about HOW AMAZING the latest GPT-4 update was or how MINDBLOWING THIS WEEK IN AI was.
I’d worked in data science/machine learning for 7 years, after all; I’d used language models and embeddings before it was cool. These cretins couldn’t even read a confusion matrix – they should be treated with the same respect as a telemarketer who calls the home landline during dinner, is probably something like how my inner monologue went.
However, in my return to the US, I was also blessed with a unique opportunity to work at the intersection of AI with many of the leading AI labs on making a nimble, AI-first product. As I look back at the past 9 months, I think I’ve made more impact than at any other role in my career. And, my brothers in Christ, two months ago, I must report with to-be-defined levels of irony that I have made this my Twitter/Slack profile pic:

And since I genuinely have learned a lot working in the AI industry over the past 9 months, I find it useful to write down my thoughts (lest I don’t know what I really think), here I am writing a recap on what I’ve learned working in AI for the past 9 months, haters be damned!
Traditional software platform dynamics still dominate. Unless you’re building a foundational AI lab, the largest expense you will incur in building an AI product is going to be your team. [1] So, effectively, most AI products, like the wave of cloud products before them, have a near-zero marginal cost of serving an additional user, creating familiar dynamics. [2] One implication of this is, as with past cloud platform businesses, the rich will continue to get richer. With 500 million monthly active users, ChatGPT can outinvest basically everyone in refining every interaction flow and hard edge in their general purpose AI assistant, so don’t bother competing with them on that – not even Anthropic (the #2 AI lab by revenue share) really seriously does! [3] The rest of us need to be specific and create a defensible niche, whether that’s vertical-specific or domain-specific (a.k.a. make something people want, do things that don’t scale…is this sounding familiar?).
The market for AI inference is a series of 3-month monopolies. The capability-cost frontier for new model releases is constantly evolving, i.e. the best model for adding topic labels to content for some downstream ML classification task changes every ~3 months. For those unfamiliar, the capability-cost frontier is displayed here as the orange line, representing, at each level of cost in terms of $ per million tokens, the maximum “intelligence” you can get:
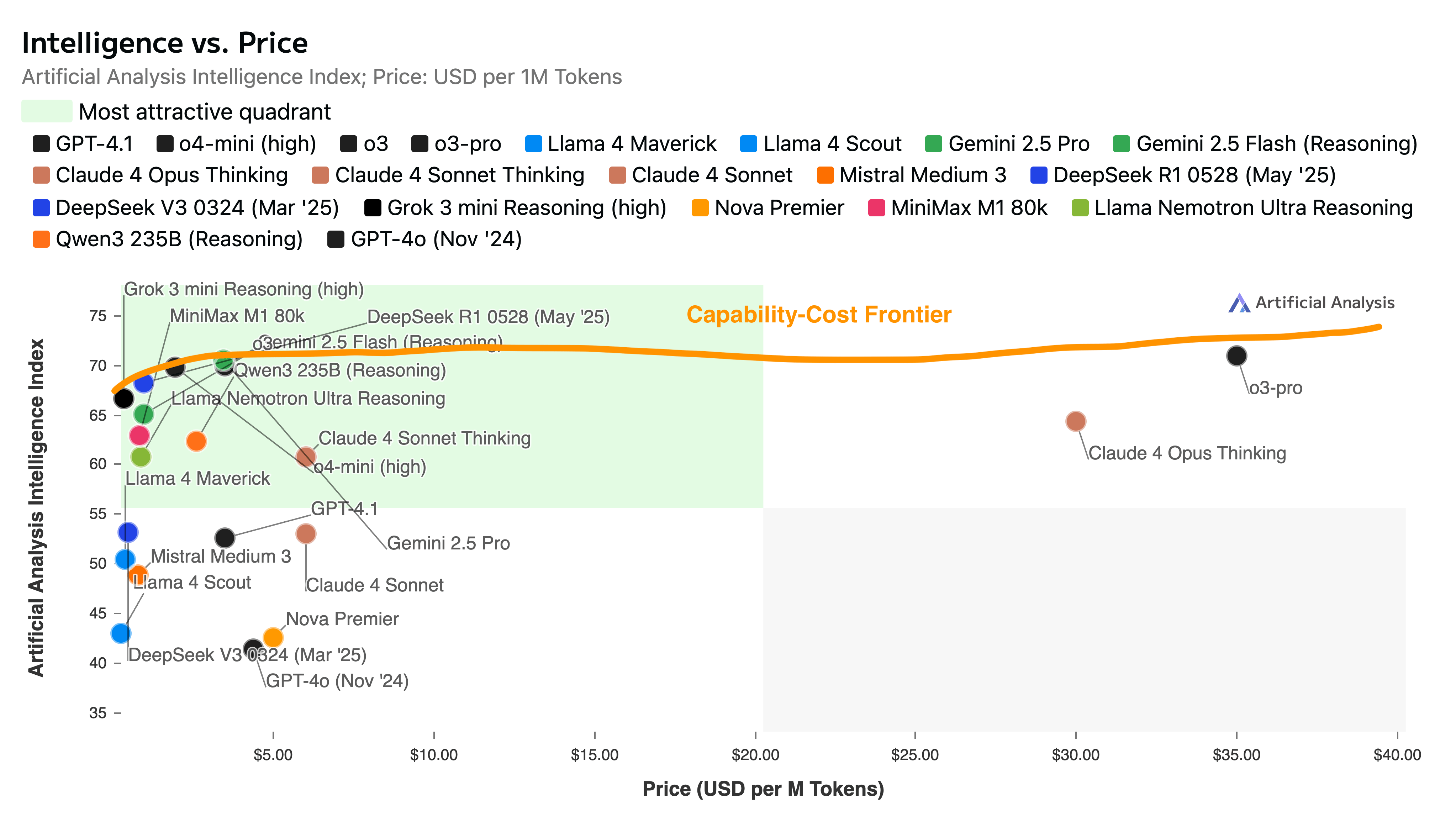
However, note that intelligence here is measured basic on a private eval set and the frontier in this case seems to show that you don’t get much better performance by paying more but the shape of this curve in practice varies based on problem domain. One consequence of this is that comparing all AI models’ prices across the board is more meaningful for segmenting them than for actual competition/substitution. That is, no one uses Opus 4 (one of the most expensive models in the world as of the time of this writing) for a classification task so its price vs. Gemini 2.5 Flash (the current default for many classification tasks) is basically irrelevant. But if it’s the best model at the specific software design problem you’re working on at the moment, Anthropic can basically charge whatever they want to…for now, until someone else comes out with a better model for your problem…and changing prices is pretty disruptive…so these are all of the things I imagine frontier labs are thinking about when setting prices, beyond true cost of inference. The more profound consequence of this is that you really want to invest in ways that make swapping out models easy like good abstractions, encapsulation, and evals to benefit from the growing model diversity.
Many social norms are going to change very rapidly, and are already in fact out of date. This is so trite that I worry it’ll be ignored but I really think the next 2 years are about to blow people’s minds. Whereas crypto promised use cases for 10 years and never delivered, AI is going to over-deliver in really uncomfortable, profound ways. One simple example is how using AI right now (e.g. in performance reviews, professional communication, homework, etc.) is still seen as lazy/low status/bad. I expect this will turn with the academic setting being the last to fall (for a mix of good reasons and intransigence). Another example is how in the past photorealistic AI-generated content (e.g. image/video) was always below the quality threshold that could be detected with the naked eye. Products like HeyGen, Veo3 and Synthesia are so rapidly advancing on these fronts that in 1-2 years I expect we will probably have to learn to distrust any content online (especially from public figures) that doesn’t contain an authenticity signature like Google’s SynthID. A final example is that there’s been an implicit expectation of privacy in virtual meetings in workplaces, but with the rapid adoption of tools like Granola/Notion audio notes that inject themselves into system audio, this is no longer valid – all of us are now celebrities possibly being recorded by infinitely patient AI paparazzi. The same I believe may become true for physical spaces with the growth of physical products like Meta Raybans/Rabbit R1/Snap’s glasses; I simply don’t think the cultural forces that made the Google Glasshole meme will be able to resist this time.
This post doesn’t represent any views of my employers or any company I’m affiliated with.
[1] What about Cursor, you say? I expect this is true even for the home-run AI product outliers, who surely have insane inference bills, when you accurately account for non-cash employee comp expense (e.g. RSUs), especially at the most recent valuation levels. Now, some of that “expense” aligned incentives and created equity value so it probably shouldn’t all be written off as a full expense, but probably most of it should be since it represents the opportunity cost of giving that equity to someone else (i.e. another employee, selling it to an investor).
[2] This assumes you’re not operating at too negative of a gross margin, which seems reasonable even for the most aggressive, well-capitalized AI companies like Perplexity who reportedly consider it a defensible accounting practice to capitalize inference expense. (FWIW, I do not.)
[3] The only exceptions are basically Google and Meta imho. Google has scrambled since the nauseating Gemma days to become a legitimate third horse in the AI frontier lab race, but are still struggling in the general purpose AI assistant race (i.e. when you strip out the AI usage that’s coming from hard bundling into existing products). Meta is a distant fourth/fifth in the AI frontier lab race but the Meta Raybans are contrastingly probably the most successful AI/augmented reality physical product in the US, especially vs. Apple’s Vision Pro.